I’ve been learning PyTorch extensively and believe the best approach
is to combine physics with machine learning. My goal in this article is
to show how to model a lens while enforcing physical constraints, so it
reproduces a custom pattern via caustics, that is, the rays of light
passing through the lens and focusing in specific directions. This
problem appears simple but conceals considerable mathematical
complexity, which I will explain step by step. The code is publicly
available at the following link.
The setup: a lens with a two free-form surfaces, thickness
,
and radius
is positioned at distance
from a screen where the caustics are projected. The reference axis is
defined so that the axis through the lens center is positive when moving
away from the screen; thus
is the screen and increases toward the back of the lens. A parallel
bundle of rays from infinity strikes the lens under geometric optics, so
we treat light only by refraction (Snell’s law), neglecting diffraction
because the aperture is much larger than the wavelength. We seek the
mathematical formulation, subject to physical constraints, for the front
surface height
that produces the desired screen pattern; the lens is glass with
refractive index
.
Given this setup, the goal is to ensure the surface distribution of
light intensity projected by the lens shape
closely matches a specified target distribution, which is the pattern we
intend to recreate. To do this, we must first understand, in practical
terms, the formulas and procedures for tracking the positions of light
rays as they propagate through the lens and project onto the screen.
First of all, the light rays come from infinity and all parallel, as
a bundle, with a direction versor
directed to the
of the projection surface. Each ray is coming from a specific point
along the
and
axes,
and
,
respectively. They intersect the lens surface at a generic position
This makes the intersection point between the front surface of the
lens given in coordinate space by
To apply Snell’s law, refracting the ray, we need to find the surface
normal
at that point, technically given by
where
is the surface function. This means we need to calculate the
gradients of the height function. Because we can express the height
function in a differentiable form using Zernike polynomials, PyTorch
automatic differentiation computes each component of the derivative,
making the calculation trivial. Then, the ray passes from the front
surface of the lens through the glass: Snell’s law says that the
direction of propagation of light within the glass lens,
,
upon hitting the surface, is related the
by the refractive index of the glass,
,
as
by definition. Through geometric identities based on the dot product
it’s possible to derive that
where
After it’s calculation, this needs to be normalized. To find where
the ray hits the back surface of the lens, we need to solve the
equation
for
,
which yields the intersection point
At the back surface
a second refraction occurs as light exits the lens back into air.
Again we apply Snell’s law, but now the refractive index ratio is
The back surface normal
is computed identically from the gradient of
,
and the refracted direction in air is
where
Finally, the ray propagates from
in direction
until it hits the screen at
.
The screen intersection is simply
where
The
coordinates of
determine where the ray contributes intensity to the caustic
pattern.
Zernike Polynomial
Parameterization
The critical question is: how do we represent
and
in a form that is both differentiable and physically reasonable? The
answer lies in Zernike polynomials, an orthogonal basis
over the unit disk that are standard in optical surface description. A
Zernike polynomial
is indexed by radial degree
and azimuthal frequency
,
where
is the normalized radial coordinate and
is the angular coordinate. The polynomial is defined as:
where
is the radial polynomial:
Each surface is expressed as a weighted sum:
where the coefficients
are the learnable parameters optimized by PyTorch. For instance, with
maximum radial order
,
we obtain 28 Zernike modes per surface. Low-order modes (e.g.,
corresponding to defocus) have large-scale effects, while high-order
modes introduce fine features. To compute the surface normal, we need
.
PyTorch’s automatic differentiation transparently handles this: during
the forward pass, we simply call backward() and PyTorch
computes
for each coefficient, propagating gradients through the entire
ray-tracing pipeline.
Differentiable
Histogram via Gaussian Splatting
After tracing
rays, we obtain a set of screen hit positions
with validity weights
indicating whether ray
successfully reached the screen (some rays may undergo total internal
reflection or miss the screen bounds). To compare against the target
pattern, we must convert these discrete points into a continuous 2D
intensity distribution. Traditional histogram binning is
non-differentiable due to the discrete assignment of points to bins.
Instead, I use Gaussian splatting: each ray
contributes a Gaussian kernel centered at
to nearby grid cells. Formally, the histogram at grid cell
with center
is:
where
is the kernel width (typically 1-2 grid cells). This operation is fully
differentiable: gradients flow from
back to
,
then through the ray-tracing equations to the Zernike coefficients. The
choice of
balances resolution and smoothness; smaller
gives sharper features but noisier gradients.
Loss Function Design
The optimization objective is a weighted combination of several
terms, each enforcing different physical and aesthetic constraints. The
primary term is data fidelity, which measures how closely the predicted
histogram
matches the target
.
I use a combination of L1 loss
for robustness and Sinkhorn divergence
for spatial transport. The Sinkhorn divergence, an entropic
approximation to the optimal transport distance, is particularly
effective because it measures the “work” needed to transform one
distribution into another, naturally handling spatial shifts. It is
computed via iterative Sinkhorn scaling:
where
is the cost matrix and
is the entropic regularization parameter (typically 0.01). This
converges in approximately 100 iterations.
Surface smoothness regularization prevents unphysical high-frequency
oscillations by penalizing high-order Zernike coefficients more heavily
via
where
is the radial degree of mode
.
This biases the optimizer toward low-order aberrations, which are easier
to manufacture. To ensure the predicted pattern has similar spatial
spread as the target, I match both the Shannon entropy
and the second spatial moments (variance). Rays undergoing total
internal reflection fail to reach the screen, reducing light efficiency,
so the term
encourages designs that minimize TIR, where
is the fraction of rays that successfully reach the screen. Finally, a
surface separation constraint ensures the two free-form surfaces
maintain a minimum separation
(e.g., 0.5 mm) to prevent physical overlap. I sample random points
across the aperture and penalize violations via
The total loss is
where the weights
are hyperparameters tuned to balance competing objectives.
Optimization Loop
The optimization uses the Adam optimizer with learning rate
and a ReduceLROnPlateau scheduler that halves the
learning rate when the loss plateaus for 50 iterations. Gradient
clipping (max norm = 1.0) prevents instabilities from sharp refractions.
A typical run executes 500-1000 iterations, taking a few minutes on a
GPU. Each iteration:
- Samples ray entry points uniformly on a grid within the lens
aperture
- Traces rays through both lens surfaces using the current Zernike
coefficients
- Creates the predicted histogram via Gaussian splatting
- Computes the loss
- Backpropagates gradients through the entire pipeline to update
Zernike coefficients
The code exports the optimized lens surfaces as STL files for 3D
printing and generates animated GIFs showing the caustic pattern
evolving during optimization.
Results and Observations
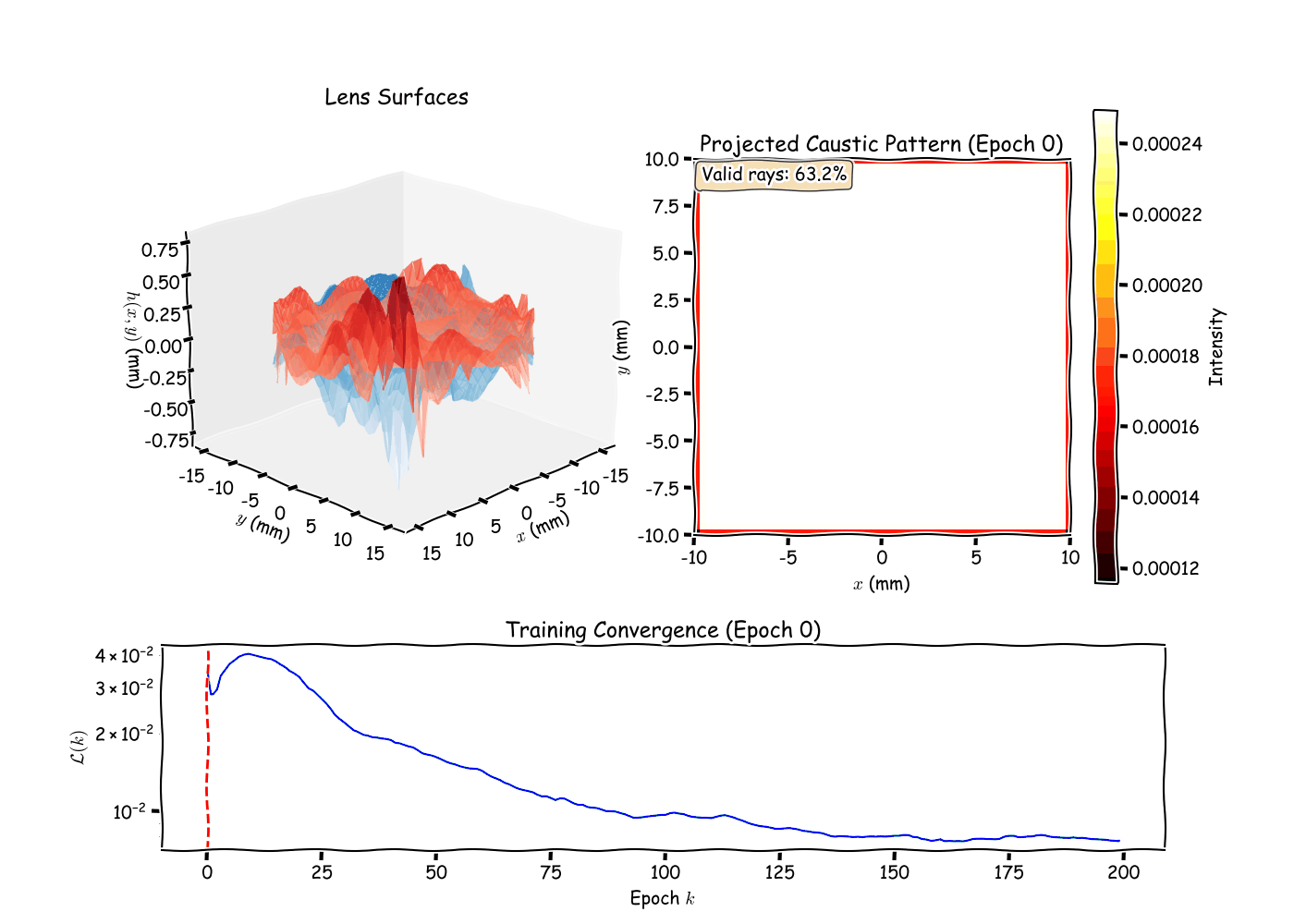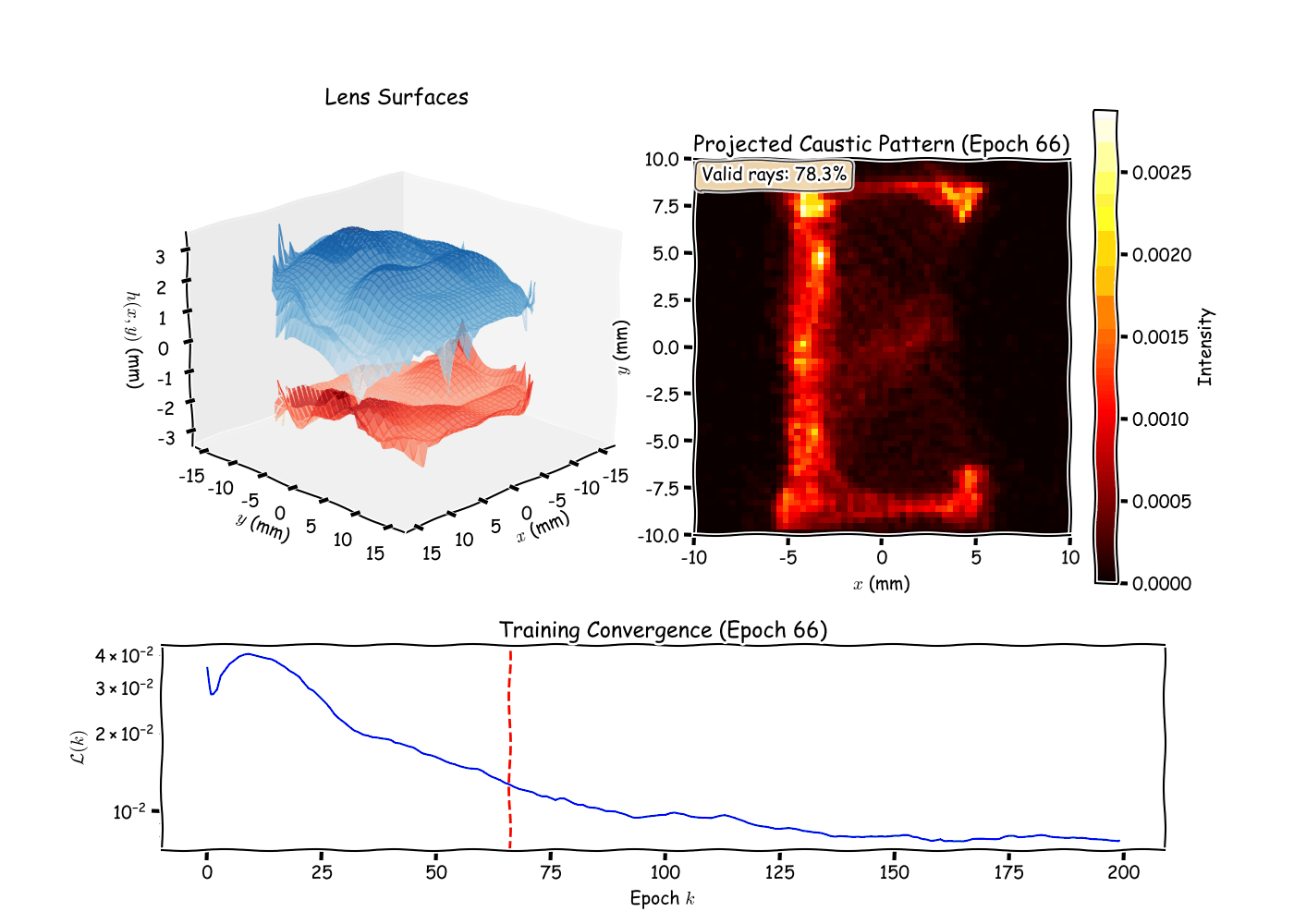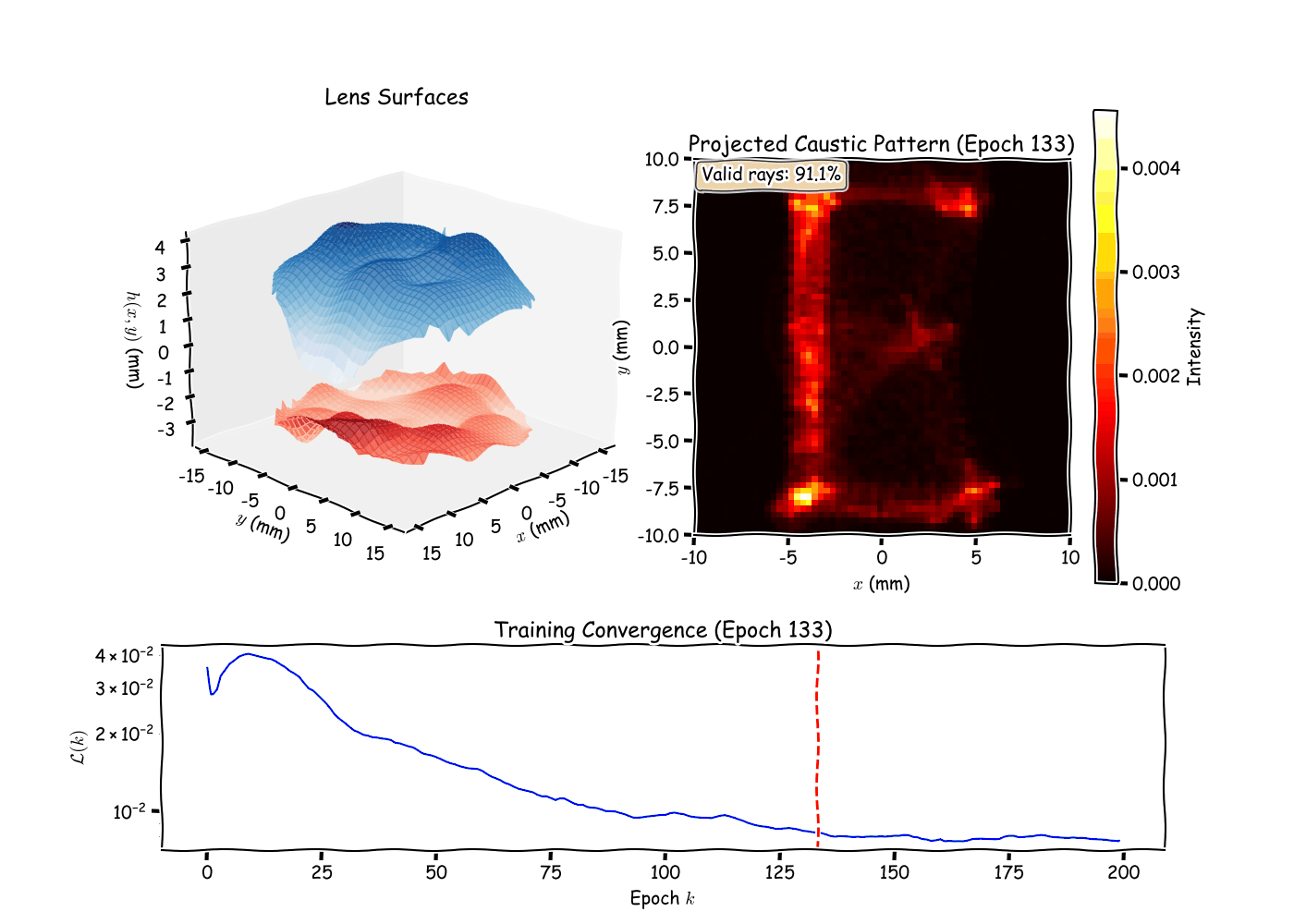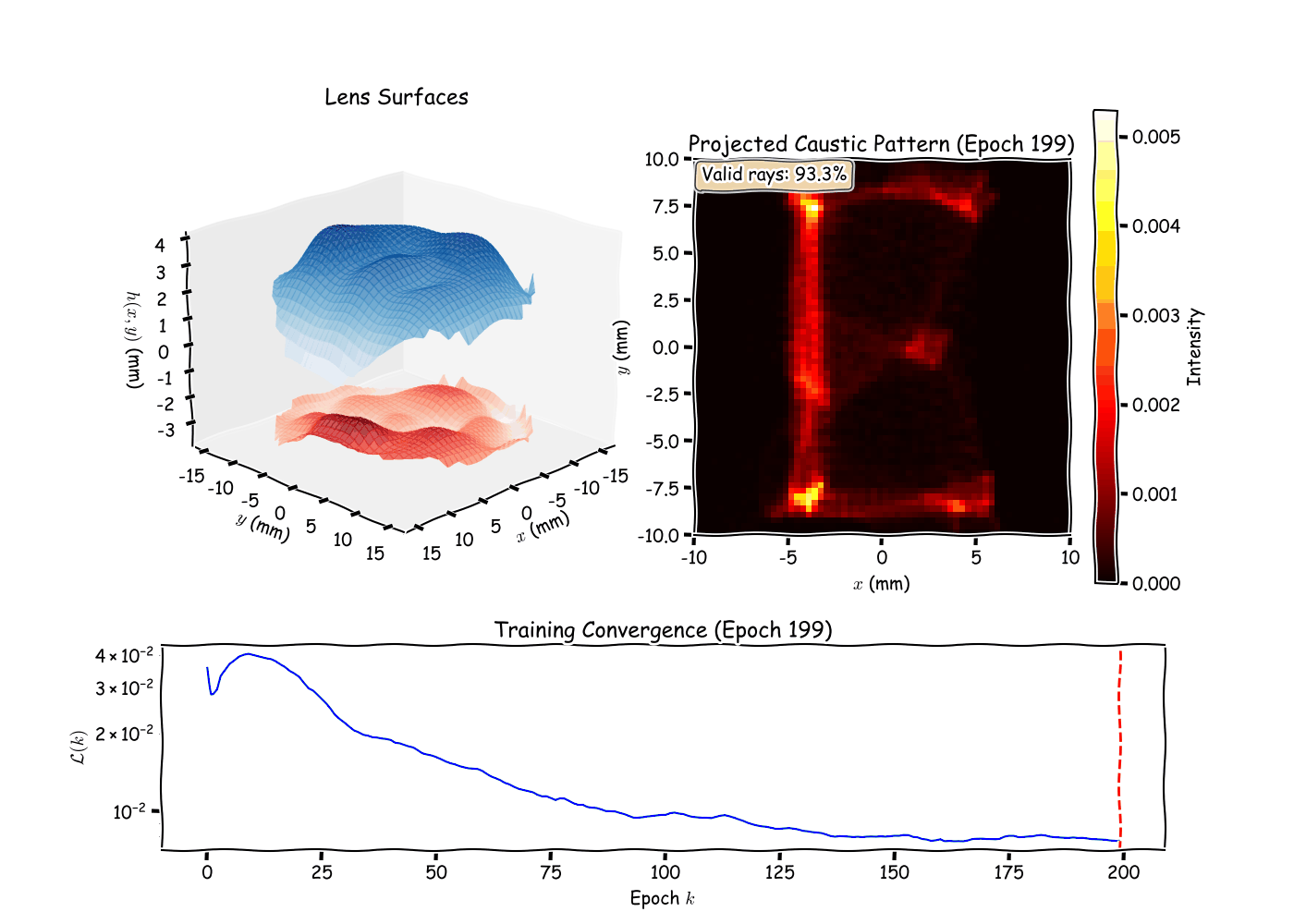
Running the optimizer on a target pattern (e.g., a logo or simple
shape), I observe several phenomena. The loss typically decreases
rapidly in the first 100 iterations as low-order Zernike modes (defocus,
astigmatism) adjust the overall ray distribution. Later iterations
refine fine details via higher-order modes, demonstrating the
hierarchical nature of the Zernike basis. The Gaussian splatting kernel
width
directly controls pattern sharpness: smaller
produces crisper edges but requires more rays to avoid noisy gradients,
revealing a fundamental tradeoff between resolution and optimization
stability. The surface separation penalty proves crucial in practice,
without it, the optimizer occasionally produces overlapping surfaces
that are physically impossible to manufacture, highlighting the
importance of encoding domain constraints directly into the loss
function. Like most non-convex optimizations, the final result depends
on initialization. Starting with negative defocus (concave front
surface) helps spread rays, providing better initial coverage of the
screen and reducing the likelihood of getting trapped in poor local
minima.
This project demonstrates how modern automatic differentiation
frameworks enable inverse design in classical physics domains. The key
insight is that ray tracing, despite involving geometric intersections
and conditional logic, can be made differentiable through careful
formulation. The same approach extends naturally to more complex optical
systems, adding more refractive surfaces, diffractive elements, or
wavelength-dependent dispersion simply requires expanding the forward
model while PyTorch handles the gradient computation automatically.