To better learn PyTorch, I set out to develop an optimization program
that combines the physics of lenses with machine learning. The goal is
to design the shape of a single glass lens that takes a given bundle of
parallel incoming light rays and focuses them to a single, theoretically
infinitesimal point on a screen at a specified distance.
Physics of Ray Optics
Because the apertures have diameters hundreds of times larger than
the wavelength of light, we operate in the regime of geometrical optics,
which treats light as rays. The underlying assumption is that light
travels in straight lines within a uniform medium and that each ray is
independent, with no interactions between rays. Wave effects such as
diffraction and interference are neglected because the lens features are
large compared with the wavelength. However, we will apply the full
Snell’s law rather than the paraxial approximation, so the model remains
accurate for rays at steep angles relative to the optical axis.
A light ray is mathematically represented by a vector with a given
origin
and a normalized direction
where
.
The position along the ray can be parameterized by the distance
traveled:
This parametric form is computationally convenient because finding
where a ray intersects a surface reduces to solving for the scalar
.
A lens is defined by two spherical surfaces separated by a thickness
,
each surface specified by its curvature
where
is the radius of curvature. The front surface has curvature
with vertex at
,
and the back surface has curvature
with vertex at
.
A positive curvature means the center of curvature lies in the
direction from the surface vertex. For a sphere centered at
,
the implicit equation
can be solved for the sag (the z-displacement from the vertex):
where
.
Rewriting in terms of curvature and rationalizing to avoid numerical
instability when
:
This is the non-paraxial sag formula, valid for all ray heights. The
paraxial approximation
is only accurate for small
.
To apply Snell’s law at a surface, we need the normal vector. For a
sphere centered at
,
the outward normal at any point
is simply:
Snell’s law states that when light passes between media with
different refractive indices, it bends according to
.
For computation, a vector form is more practical. We decompose the
incident ray
into components parallel and perpendicular to the surface:
where
and
.
The magnitudes relate to angles:
and
.
With
,
the refracted direction becomes:
where
and
.
A crucial edge case appears when the term inside this square root
becomes negative. This occurs when light travels from a denser to a less
dense medium at a sufficiently shallow angle, beyond the critical angle
.
For glass
()
to air,
.
Beyond this, Total Internal Reflection (TIR) occurs and the ray never
exits the lens.
The Computational Model
With the physics established, we can build an algorithm to trace rays
through the lens. To properly sample the lens aperture, we need rays
distributed uniformly across a circular cross-section. A naive approach
using concentric rings creates artificial clustering. Instead, we use
the Vogel spiral distribution: for
rays indexed by
,
the polar coordinates are
and
,
where
is the golden angle. The
scaling ensures uniform area density since area grows as
.
All initial ray directions are set to
for a collimated beam.
The first step in tracing is determining where a ray hits a surface.
For a differentiable implementation, an iterative Newton-Raphson method
is more numerically stable than the closed-form quadratic solution and
generalizes to arbitrary surface shapes. We seek the root of
,
iterating
.
The derivative is:
Starting from an initial guess at the planar intersection, 3-5
iterations suffice for convergence.
The full ray-tracing algorithm proceeds as:
- Find intersection
with front surface
via Newton’s method
- Verify
(ray hits the lens)
- Compute normal
,
apply Snell’s law to get refracted direction
,
check for TIR
- Find intersection
with back surface
- Verify aperture, compute normal
(negated since we’re exiting), apply Snell’s law for
- Propagate to target plane:
where
A ray is valid if it passes all aperture checks, experiences no TIR,
and
.
Optimization with PyTorch
We have three parameters,
,
,
and
,
and a complex simulation mapping them to a spot size. How do we find
optimal values? Brute-force search over continuous parameters is
hopeless. Gradient descent is smarter: if we know how the spot size
changes when we tweak each parameter, we can iteratively adjust them to
reduce it. The quantity we need is the gradient:
where
is a loss function measuring lens quality. We define
as the mean squared distance of ray endpoints from the origin:
This equals the squared RMS spot radius. We also add a penalty
to discourage configurations where rays undergo TIR.
The structure of the optimization is straightforward:
- Initialize parameters
and mark them as requiring gradients
- Repeat until convergence:
- Run the ray tracer: Obtain
for each ray from running the ray tracer as a function of the parameters
- Compute loss:
- Backpropagate: compute
automatically
- Update the parameters:
The code module contains all the physics, Newton’s method, Snell’s
law, propagation, but to PyTorch it’s just a sequence of primitive
operations (multiply, add, sqrt,
divide) whose derivatives are known. By marking parameters
as “requiring gradients,” every operation gets recorded into a
computation graph. Calling backpropagate then walks through this graph
in reverse, applying the chain rule to compute how much each parameter
contributed to the final loss.
Computing
by hand would require pages of chain rule through Newton iterations,
Snell’s law, and thousands of rays. PyTorch automates this entirely. To
illustrate, consider a toy example
.
Letting
:
When we call L.backward(), PyTorch walks backward
through this graph applying the chain rule:
For our full ray tracer, the graph contains hundreds of operations
from Newton iterations, Snell’s law, and averaging. PyTorch traverses it
automatically, computing all gradients without us writing derivative
code. One subtlety is that the derivative of
is
,
which explodes as
.
We use a regularized square root
with
to bound gradients.
We mark parameters for optimization using
torch.nn.Parameter, telling PyTorch to track computations
involving them. The optimizer we use is Adam, which maintains adaptive
per-parameter learning rates based on gradient statistics. It tracks
exponential moving averages of gradients
()
and squared gradients
(),
applying bias correction before updating:
The optimization loop is: zero gradients, run forward pass (building
the graph), compute loss, call backward() (computing
gradients via chain rule), call optimizer.step() (updating
parameters), repeat.
Results
The optimization started with a symmetric biconvex lens with initial
curvatures
and
(corresponding to radii
mm and
mm), and thickness
mm. Initial loss was
(RMS spot radius
mm). After 300 iterations, the loss dropped to
(
mm), a 100× improvement. The final curvatures correspond to radii
mm,
mm, with thickness
mm. The optimizer slightly increased both curvatures (shorter radii) and
reduced thickness. Valid rays remained at 100% throughout.
The solution reveals interesting physics. Starting symmetric
(),
the optimizer converged to a slightly asymmetric configuration, its
attempt to minimize spherical aberration. The Coddington shape factor
shifted from
to
.
For a single lens focusing collimated light, theory predicts an
asymmetric shape is optimal, and the optimizer discovered this
independently.
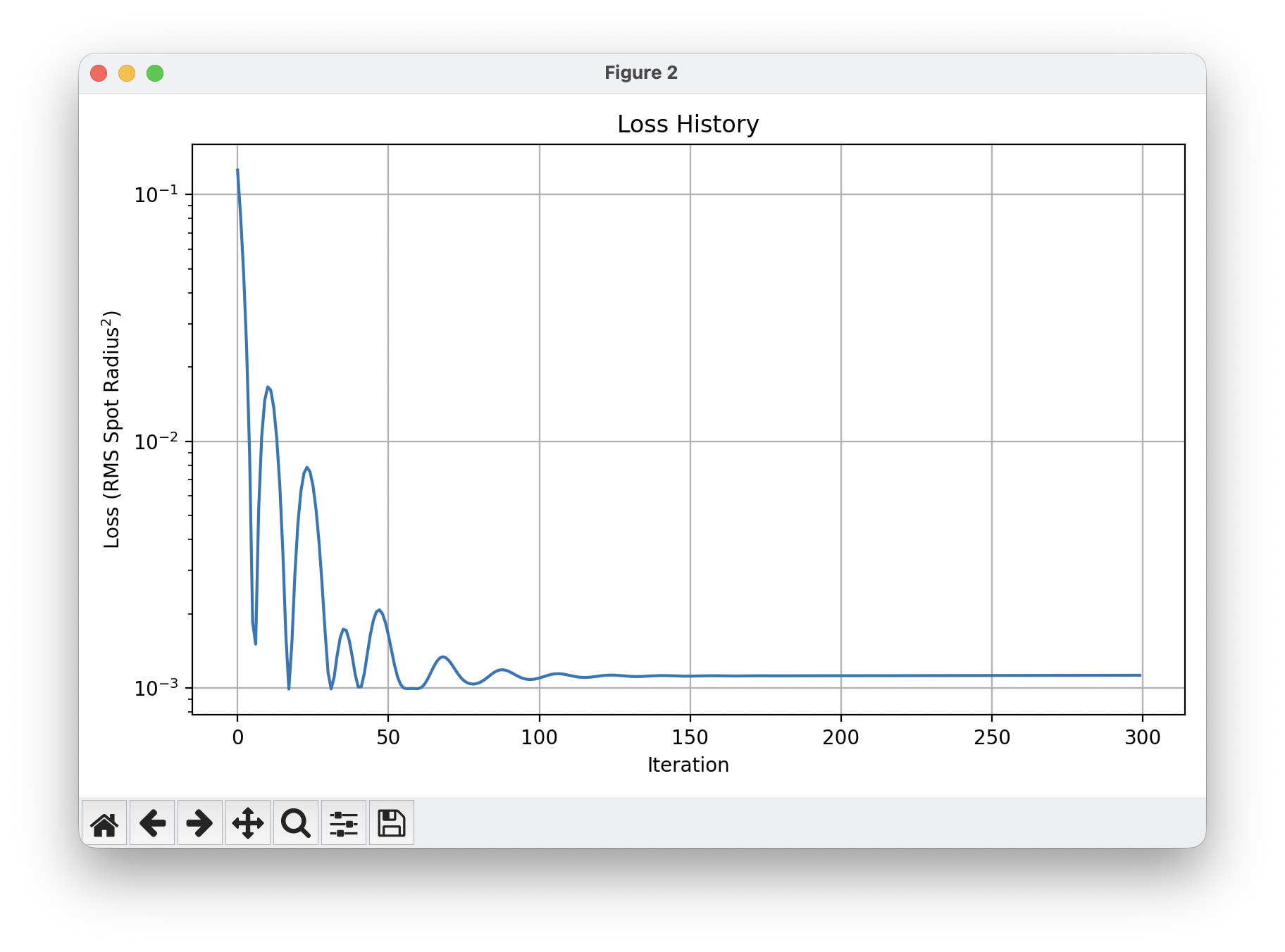
The loss history shows characteristic dynamics: rapid exponential but
oscillatory descent in early iterations as large gradients drive big
steps, then slowing convergence as the minimum is approached, finally
plateauing around iteration 150. Convergence in ~100 iterations (rather
than thousands) demonstrates the efficiency of gradient-based
optimization on smooth, differentiable problems.
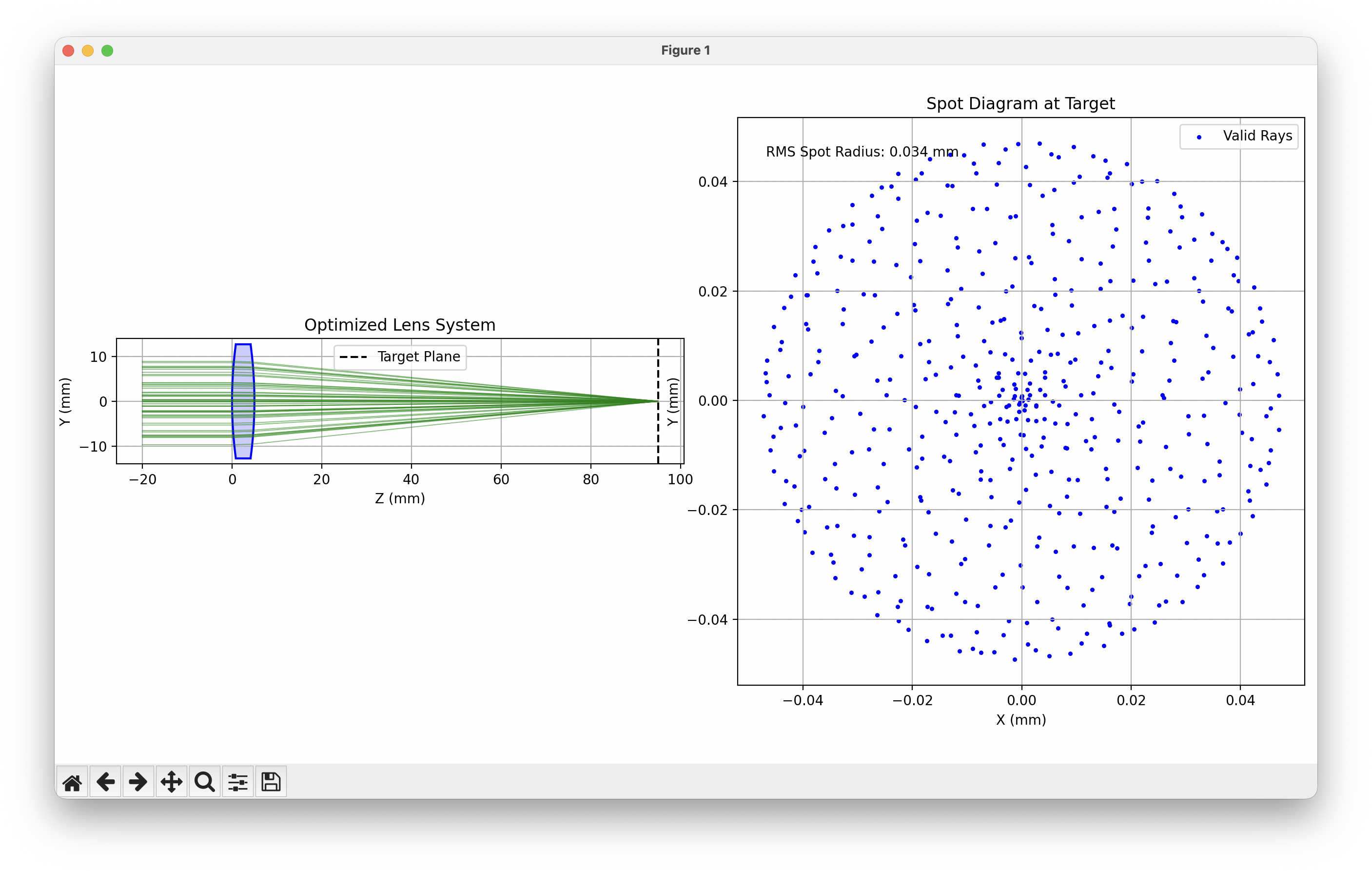
The first figure shows a side view of the optimized lens with ray
paths converging to a tight spot, alongside the spot diagram showing
final
positions on the target, zoomed in where they’re appearing.